|
Welcome to part 3 of the DXT compression series. In this series I go over the techniques and results used to compress Firefall's texture data as they are uncovered and implemented. In this post I go over some simple data transpose options with some rather non-intuitive results. Previous posts on this topic: Part 1 - Intro Part 2 - The Basics Part 4 - Entropy In the last post we determined the baseline of straight up LZMA compression on DXT5 data, which is 2.28bpp on average for my test data set from Orbital Comm Tower in Firefall. Transposing DXT5What is a transpose of the DXT5 blocks? The conversion from an array of structures (AOS) to a structure of arrays (SOA). // array of structures (AOS) struct { unsigned char alphaLineStart; unsigned char alphaLineEnd; unsigned char alphaSelectionBits[6]; unsigned short colorLineStart; unsigned short colorLineEnd; unsigned int colorSelectionBits; } dxt5Blocks[1024]; // structure of arrays (SOA) struct { unsigned char alphaLineStart[1024]; unsigned char alphaLineEnd[1024]; unsigned char alphaSelectionBits[1024*6]; unsigned short colorLineStart[1024]; unsigned short colorLineEnd[1024]; unsigned int colorSelectionBits[1024]; } dxt5Blocks; Conversion to SOA should be better for compression, because similar elements are adjacent to each other. That is rather than the default of interleaved with elements which are related, but have different statistical properties. We have 3 textures of DXT5 blocks with 6 components for each block.
I attempted compressing the following permutations of these components:
An alternate variation is grouping the color start and end points together and treating them as a pair. This gives 4 different components to a DXT5 block:
I tested the following permutations with this variation of logical DXT elements:
There is also another variation that is better @ 2.26bpp and also is faster perf wise. You can combine the color line and alpha line into one data set (non-interleaved).
I tried a few other variations but overall, 2.26bpp was the best. The question still remains though, which method described above is most complementary to the baseline? As in, which does the best job at compressing stuff that the baseline does not? 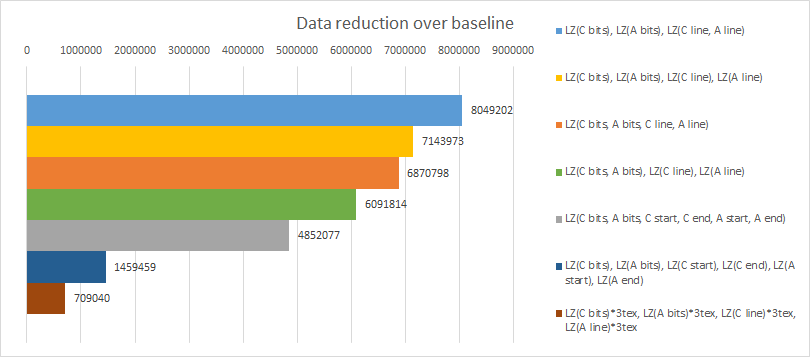 The conclusion...
The best complementary transpose @ 2.26bpp is LZMA compression with knobs
The down side is that on average transposing does not make compression significantly better when compared with optimally tuned straight up LZMA. The up side, if you switch between baseline and the best complementary transpose conditionally, you can get the size down a small bit further to 2.25bpp. A small, but expected improvement of about 0.5%. If however you do not have the option to optimally tune LZMA knobs (transferring to a web-browser over Javascript via gzip), trying out the best complementary layout may give better results than the more typical transpose all elements in some cases. As always, be sure to measure and test your own data sets.
8 Comments
Bryan McNett
7/16/2013 08:36:16 am
Nice rundown of LZW's ability to compress DXT textures. Did you try isolating the individual color channels, too? I know you said that you didn't want to go lossy, but here's an idea nobody seems to have explored yet:
Jon Olick
7/16/2013 08:48:36 am
> Did you try isolating the individual color channels, too?
Bryan McNett
7/16/2013 10:42:59 am
>>palletize the endpoints
Jon Olick
7/16/2013 11:24:03 am
Ah, nm. yeah. I don't believe anybody has tried that yet. I don't have easy access to the higher mip's data, so maybe not applicable to Firefall without additional RAM usage to keep that information around. Sounds like a really good area to investigate if you do have that though.
Jon Olick
7/16/2013 11:30:22 am
According to https://code.google.com/p/crunch/wiki/TechnicalDetails
cb
7/17/2013 01:51:58 am
Jon - LZMA creates sort of a weird bias wrst transposes. Most other LZ compressors see a big win from transposes.
Jon Olick
7/17/2013 02:37:22 am
That makes a lot of sense :) I was pretty surprised at exactly why LZMA performed so well.
nf
7/18/2013 10:26:07 pm
LZ on whole blocks allows it to operate like a context coder within that block, there is a strong contextual relationship between start- and end-points fe. If you divide the blocks into two+ streams you loose the intra-block context and replace it by inter-block context. By the very nature of LZ it just can't cope with the latter that well on regular noisy DXT. Leave a Reply. |
Archives
November 2021
Categories |
 RSS Feed
RSS Feed